Web Document Viewer allow to save the document along with optional annotations data and filled PDF forms. All document structure changes, like adding, removing and reordering are reflected in the result saved document.
JavaScript save API
There are two ways to trigger document save on the JavaScript side.
- Through default UI.
Whensavepathconfig option is specified, "Save" button will appear on the document toolbar.
There are two config options that affects default save behavior:savepath- path to the directory where documents will be saved on server.savefileformat- The default file format for the document that will be used when saving multipage document to the server.
The following formats are supported: pdf, tiff (or tif), jpeg (or jpg), png, bmp, tga, pcx, psd, tla, wbmp, emf, wmf.
- Through
WebDocumentViewer.saveAPI. This method allows to override default config options descried above and pass callback function that will be triggered when save complete.
Server Side API
Default server side behavior assumes that document identifiers point to the document file on server file system - for the saved document and all pages that has pages inserted from external documents using JavaScript API.
In this case, all required document pages are available from file system, document is saved to the file using following path generation pattern {savepath}/{subpath}/{fileName}.{savefileformat}. If savefileformat is not specified, original file extension is used.
Customizing Save Behavior
Default save behavior could be customized by handling WebDocumentRequestHandler.DocumentSave event. The DocumentSaveEventArgs event arguments exposes the following properties:
-
RandomAccessImageSource ImageSource { get; }
Image source that allows to retrieve all document pages asAtalaImageobjects. The order of images in this image source correspond to the order of document pages after all structure modifications done using JavaScript API. All the required data like burned annotations or filled pdf forms will be already rendered on the returned images.
Images returned by this source are not loaded into memory until they are requested by the application code.
Usually it's not recommended to use this way of retrieving page image unless application require individual page images instead of multipage document. Default save implementation optimizes save process of known document formats like, PDF or TIFF which allows to avoid encoding/decompressing original pages toAtalaImagewhich shows better performance.// Example of using ImageSource as the image provider. public class WebDocViewerHandler : WebDocumentRequestHandler { public WebDocViewerHandler() { DocumentSave += HandleDocumentSave; } void HandleDocumentSave(object sender, DocumentSaveEventArgs e) { // prevent default save to file on web server. e.PreventDefaultSaving = true; var imagesource = e.ImageSource; var destPath = Path.Combine(HttpContext.Current.Server.MapPath(e.SaveFolder), Path.GetFileNameWithoutExtension(e.FileName)); if (!Directory.Exists(destPath)) Directory.CreateDirectory(destPath); int i = 0; ImageEncoder encoder = new PngEncoder(); while (imagesource.HasMoreImages()) { using (var image = imagesource.AcquireNext()) { // could be saved for example to the database. var filename = Path.Combine(destPath, ++i + ".png"); using (var stream = File.OpenWrite(filename)) { encoder.Save(stream, image, null); } } } } } -
Stream DocumentStream {get; set;}
Output stream to write saved document. This stream is managed by the application and could be provided to override default output destination. When save is complete,WebDocumentRequestHandler.DocumentStreamWrittenis fired to notify application that stream ownership is returned back to it. -
Stream AnnotationStream {get; set;}
Output stream to write document annotations. This stream is managed by the application and could be provided to override default annotations destination. When save is complete,WebDocumentRequestHandler.AnnotationStreamWrittenis fired to notify application that stream ownership is returned back to it. -
string SaveFolder { get;}
Gets the relative folder path where the file will be saved. -
string FileName { get;}
Gets the name of the document being saved, without the file extension, if document url maps to valid file path on the server. If document url contains invalid path characters, it's set as FileName value without modification. -
string SaveFileFormat {get; set;}
The format to save the document into. This property is populated with value passed from JavaScript and could be modified byDocumentSaveevent handler. -
bool PreventDefaultSaving {get; set;}
Flag indicating whether default save behavior should be applied after event fires. In case if all required operations was done duringDocumentSaveevent handler, this flag should be set to preventWebDocumentRequestHandlerfrom trying to save document to file.
Default isfalse. -
bool Overwrite {get; set;}
Flag indicating whether output file should be overwritten if it's already exist. This applies to default save behavior which saves document to the file system on the server.
Default istrue. -
IDictionary<string, string> Params { get; }
Additional application-specific parameters passed from JavaScript along with this save request onsavefunction call.
Save file with different file extension
WDV server handler always sets file extension according to image type during save operation. With a new property ReplaceFileExtensionOnSave in WebDocumentRequestHandler it becomes available to override this behavior. So for instance, if you want to preserve the original file extension, you need to set the property to value ReplaceFileExtensionOnSave.None.
Retrieving document pages
As described in previous articles, document identifier could be arbitrary application specific string that does not necessary point to file on the web server. I.e. application is responsible for providing document metadata and individual page images on demand. To correctly save documents in such scenarios Web Document viewer request handler exposes set of events that are fired during save operations to override document data retrieval.
-
WebDocumentRequestHandler.ResolveDocumentUri
Fired to request stream for the whole document for particular document identifier. This event is useful when all document pages are stored in a single file(stream). If stream is provided while handling this event,WebDocumentRequestHandlerwon't fire additional requests for this particular document identifier. All subsequent pages will be retrieved from provided stream. -
WebDocumentRequestHandler.ReleaseDocumentStream
Notifies application that particular document stream, provided while handlingResolveDocumentUriis not used by theWebDocumentRequestHandleranymore, i.e. stream ownership is returned to the application. -
WebDocumentRequestHandler.ResolvePageUri
Fired to request stream for the particular document page.
Application could provide multipage document and specify index of the requested page in that document usingResolvePageUriEventArgs.DocumentPageIndex. This could be useful when logical document consist of the multiple files, and each of them consist of multiple images. For example, if each of such files contains two sides of the duplex-scanned physical page. -
WebDocumentRequestHandler.ReleasePageStream
Notifies application that particular document stream, provided while handlingResolvePageUriis not used by theWebDocumentRequestHandleranymore, i.e. stream ownership is returned to the application.
Event described above are fired during document save when requesting data for both - "original" document(opened in the viewer) and all pages inserted from external document using JavaScript API.
The following diagram shows high-level overview of document and page streams lifetime during save operation.
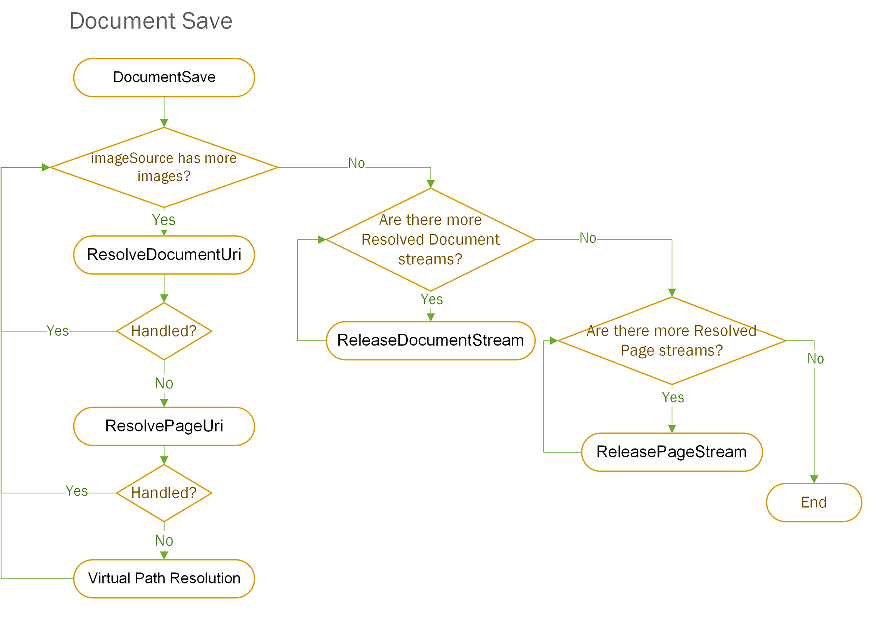
All document streams and page streams are cached inside one save request, so the same document or document page will never be requested twice. Once the document stream is resolved, all pages are taken from this stream. Once the page stream is resolved, it is taken from this stream if it occurs twice in the target document.
Customized web document viewer handler sample
Below is the simple WebDocumentRequestHandler implementation that overrides default behavior and represents the directory containing single-page documents as a single logical document.
public class WebDocViewerHandler : WebDocumentRequestHandler
{
public WebDocViewerHandler()
{
DocumentInfoRequested += CustomPageUriHandler_DocumentInfoRequested;
ImageRequested += CustomPageUriHandler_ImageRequested;
ResolvePageUri += CustomImageSaving_ResolvePageUri;
ReleasePageStream += CustomPageUriHandler_ReleasePageStream;
}
void CustomPageUriHandler_ImageRequested(object sender, ImageRequestedEventArgs e)
{
var filepath = MapPath(e.FilePath);
if (!CheckDirectoryExists(filepath))
return;
e.Image = GetImage(filepath, e.FrameIndex);
}
void CustomPageUriHandler_DocumentInfoRequested(object sender,
DocumentInfoRequestedEventArgs e)
{
// some custom code to set requered values
var filepath = MapPath(e.FilePath);
if (!CheckDirectoryExists(filepath))
return;
e.PageCount = Directory.GetFiles(filepath).Length;
using (var image = GetImage(filepath, 0))
{
e.PageSize = image.Size;
e.FormFilePath = null;
e.Resolution = image.Resolution;
e.ColorDepth = image.ColorDepth;
}
}
void CustomImageSaving_ResolvePageUri(object sender, ResolvePageUriEventArgs e)
{
var filepath = MapPath(e.DocumentUri);
if (!CheckDirectoryExists(filepath))
return;
var file = GetExistingFilename(filepath, e.SourcePageIndex);
if (string.IsNullOrEmpty(file))
return;
e.DocumentStream = File.OpenRead(file);
e.DocumentPageIndex = 0;
}
void CustomPageUriHandler_ReleasePageStream(object sender, ResolvePageUriEventArgs e)
{
e.DocumentStream.Dispose();
}
private AtalaImage GetImage(string filepath, int index)
{
var file = GetExistingFilename(filepath, index);
if (string.IsNullOrEmpty(file))
return null;
using (var stream = File.OpenRead(file))
return new AtalaImage(stream);
}
private bool CheckDirectoryExists(string path)
{
return Directory.Exists(path);
}
private string MapPath(string relativePath)
{
if (!Path.IsPathRooted(relativePath))
return HttpContext.Current.Server.MapPath(relativePath);
return relativePath;
}
private string GetExistingFilename(string path, int frameindex)
{
var files = Directory.GetFiles(path, frameindex + ".*");
return files[0];
}
}